Crop Predictor
O produto Preditivo oferece Estimativas de produtividade e qualidade da cultura.
Esta informação está disponível em diferentes formatos dependendo das necessidades de cada entidade.
Atualmente a HEMAV conta com uma infraestrutura de IA que trabalha para as culturas CANA-DE-AÇÚCAR, MILHO, SOJA, ALGODÃO, BETERRABA, VINHA e PALMA.
Os passos para poder dispor deste serviço são os seguintes.
Dados de entrada ao modelo
Os modelos devem contar com a maior quantidade de dados de entrada possíveis. Estes são divididos em diferentes blocos. Sendo um total de poder contar com 140 variáveis, associando a cada modelo as mais importantes segundo os dados de entrada.
Dados do cliente (dados reais)
Este é o bloco de maior importância. Os modelos refletem a qualidade dos dados. Se não existem uma quantidade suficiente de dados, ou estes não têm uma certa qualidade, na hora de treinar os modelos podem não chegar aos resultados esperados.
Nesta seção nos referimos aos dados que queremos que o modelo aprenda (produção, qualidade…) e é o ponto de partida para a gestão de dados (data de início de campanha, plantio e momento de colheita).
Esta seção conta com 40 dados possíveis para preencher, sendo os mais importantes:
external_reference_id: Identificador único por parcela.
season_label: Agrupamento de gestão.
latitude: Georreferenciação da parcela.
longitude: Georreferenciação da parcela.
type_id: Cultivo.
sub_type_id: Variedade.
init_date: Data de início da campanha (start_date ou plantation_date dependendo da cultura).
harvest_or_estimation_date: Data.
cut_number: Número de corte para cultivos como a cana-de-açúcar ou a palma.
production_per_hectare_real: Produção real obtida. Variável chave para a estimação do modelo de PRODUÇÃO.
prodph_lastseason: Variável calculada por nós, avaliando sempre para essa parcela a produção obtida na safra anterior.
atr_real: Atr real obtida. Variável chave para a estimação do modelo de ATR.
atr_lastseason: Variável calculada por nós, avaliando siempre para essa parcela a produção obtida na campanha anterior.
pol_real: Polarização real obtida. Variável chave para a estimação do modelo de POL.
sac_real: Sacarose real obtida. Variável chave para a estimação do modelo de SAC.
sac_lastseason: Variável calculada por nós, avaliando siempre para essa parcela a produção obtida na campanha anterior.
n_bunches_real: Nº de cachos. Variável chave para a estimação do modelo de N_BUNCHES.
plants_per_hectare: Nº de plantas por hectare. Variável importante.
irrigation_type: Sistema de irrigação empregado na parcela.
days: Dias de cultivo.
semana: Semana de cultivo.
Todas estas variáveis definirão a qualidade do modelo solicitado. É por isso que se realizam uma série de revisões que serão vistas na seção de revisão de dados.
Dados espectrais + radar
Ao conjunto de dados do modelo, é incorporado para cada data a nível semanal o valor médio da parcela dos seguintes valores espectrais e radar:
cloudcoverage: % de nuvens da parcela para o dia da visita. Apenas aplicável para os parâmetros espectrais.
sigma0: Variável de radar.
sigma0_std: Desvio padrão da variável radar. Mostra-nos a uniformidade da parcela.
ndre: Índice nitrogênio - clorofilas.
ndvi: Índice de vegetação.
ndvi_std: Desvio padrão do índice de vegetação.
b1: Bandas espectrais do sentinel 2.
b2: Bandas espectrais do sentinel 2.
b3: Bandas espectrais do sentinel 2.
b4: Bandas espectrais do sentinel 2.
b5: Bandas espectrais do sentinel 2.
b6: Bandas espectrais do sentinel 2.
b7: Bandas espectrais do sentinel 2.
b8: Bandas espectrais do sentinel 2.
b8a: Bandas espectrais do sentinel 2.
b9: Bandas espectrais do sentinel 2.
b11: Bandas espectrais do sentinel 2.
b12: Bandas espectrais do sentinel 2.
tcari_osavi: Índice de vegetação ajustado para remover a influência do solo.
gndvi: Índice de vegetação potenciando saturação no verde.
ccci: Índice de clorofila.
ndwi: Índice de estado hídrico (NDMI).
tcari: Índice relacionado com a absorção de clorofila.
osavi: O índice de vegetação OSAVI é um SAVI modificado que também utiliza a reflectância no espectro do infravermelho próximo e do vermelho.
Dados espectrais + radar (temporais)
São combinação das variáveis anteriores trabalhadas para evitar influência de nuvens, indicando temporalidade ou mudanças bruscas de dados, já que nós trabalhamos com acumulados desde o início da campanha/plantio, nos ajuda a extrair indicadores de importância.
ndvi_smoothed: Ndvi trabalhando com uma função de suavização eliminando a influência por interferência de nuvens.
ndwi_smoothed: Ndwi (NDMI) trabalhando com uma função de suavização removendo a influência pela interferência de nuvens.
ndvi_smoothed_temporal_max_diff: Diferença máxima entre semanas para o índice NDVI.
ndwi_smoothed_temporal_max_diff: Diferença máxima entre semanas para o índice NDWI (NDMI).
ndvi_smoothed_max: Valor máximo de NDVI alcançado na campanha.
ndwi_smoothed_max: Valor máximo de NDWI atingido na campanha.
ndvi_smoothed_temporal_mean_diff: Média de diferença entre semanas para o índice de NDVI.
ndwi_smoothed_temporal_mean_diff: Média da diferença entre semanas para o índice NDWI (NDMI).
ndvi_std_temporal_max_diff: Diferença máxima de variabilidade dentro da campanha.
sigma0_temporal_max_diff: Diferença máxima de valor de radar dentro da campanha.
sigma0_max: Valor máximo de radar alcançado na campanha.
sigma0_min: Valor mínimo de radar alcançado na campanha.
sigma0_temporal_mean_diff: Diferença média do radar durante a campanha.
sigma0_std_temporal_max_diff: Diferença máxima de radar durante a campanha.
ndvi_growth_first_month: NDVI máximo alcançado no primeiro mês da campanha.
ndwi_growth_first_month: NDWI (NDMI) máximo alcançado no primeiro mês da campanha.
Dados climatológicos
Os dados climatológicos são muito importantes no modelo já que nos indica a que tem estado exposta a cultura durante a campanha. As variáveis que medimos são as seguintes:
pres: Pressão média (mb).
slp: Pressão média ao nível do mar (mb).
wind_spd: Velocidade média do vento (Padrão m/s).
wind_gust_spd: Velocidade de rajadas de vento (m/s).
max_wind_spd: Velocidade máxima do vento em 2 minutos (m/s).
wind_dir: Direção média do vento (graus).
max_wind_dir: Direção da rajada máxima de vento em 2 minutos (graus).
max_wind_ts: Hora de máxima rajada de vento UTC (Unix Timestamp).
temp: Temperatura média (Celsius por padrão).
max_temp: Temperatura máxima (Celsius por padrão).
min_temp: Temperatura mínima (Celsius por padrão).
max_temp_ts: Hora da temperatura máxima diária UTC (Unix Timestamp).
min_temp_ts: Hora da temperatura mínima diária UTC (Unix Timestamp).
rh: Humidade relativa média (%).
dewpt: Ponto de orvalho médio (Celsius por padrão).
clouds: Cobertura média de nuvens [baseada em satélites] (%).
precip: Precipitação acumulada (padrão mm).
precip_gpm: Precipitação acumulada [estimada por satélite/radar] (padrão mm).
solar_rad: Radiação solar média (W/m^2).
t_solar_rad: Radiação solar total (W/m^2).
ghi: Irradiação solar horizontal global média (W/m^2).
t_ghi: Irradiância solar horizontal global total do dia (W/m^2) [Céu limpo]
max_ghi: Valor máximo da irradiância solar horizontal global no dia (W/m^2) [Céu limpo]
dni: Irradiação solar normal direta média (W/m^2) [Céu limpo]
t_dni: Irradiação solar normal direta total do dia (W/m^2) [Céu limpo]
max_dni: Valor máximo de radiação solar normal direta no dia (W/m^2) [Céu limpo]
dhi: Irradiância solar horizontal difusa média (W/m^2) [Céu limpo]
t_dhi: Irradiância solar horizontal difusa total do dia (W/m^2) [Céu limpo]
max_dhi: Valor máximo de irradiância solar horizontal difusa no dia (W/m^2) [Céu limpo]
max_uv: Índice UV máximo (0-11+).
Dados agroclimáticos
Os dados agroclimáticos são incorporados pela importância que têm no âmbito da agricultura.
bulk_soil_density: Densidade do solo a granel (kg/m^3).
skin_temp_max: Temperatura máxima da pele (C).
skin_temp_avg: Temperatura média da pele (C).
skin_temp_min: Temperatura mínima da pele (C).
temp_2m_avg: Temperatura média a 2 metros (C).
precip: Precipitação acumulada (mm).
specific_humidity: Humidade específica média (kg/kg).
evapotranspiration: Evapotranspiração de referência - ET0 (mm).
pres_avg: Pressão superficial média (mb).
wind_10m_spd_avg: Velocidade média do vento a 10 metros (m/s).
dlwrf_avg: Radiação solar de onda longa descendente média horária (W/m^2 · H).
dlwrf_max: Máxima radiação solar descendente de onda longa por hora (W/m^2 · H).
dswrf_avg: Média horária da radiação solar descendente de onda curta (W/m^2 · H).
dswrf_max: Radiação solar máxima horária descendente de onda curta (W/m^2 · H).
dlwrf_net: Radiação solar líquida de onda longa (W/m^2 · D).
dswrf_net: Radiação solar líquida de onda curta (W/m^2 · D).
soilm_0_10cm: Média do conteúdo de umidade do solo de 0 a 10 cm de profundidade (mm).
soilm_10_40cm: Média do conteúdo de umidade do solo de 10 a 40 cm de profundidade (mm).
soilm_40_100cm: Média do conteúdo de umidade do solo de 40 a 100 cm de profundidade (mm).
soilm_100_200cm: Média do conteúdo de umidade do solo de 100 a 200 cm de profundidade (mm).
v_soilm_0_10cm: Conteúdo volumétrico médio de umidade do solo de 0 a 10 cm de profundidade (fração).
v_soilm_10_40cm: Conteúdo volumétrico médio de umidade do solo de 10 a 40 cm de profundidade (fração).
v_soilm_40_100cm: Teor volumétrico médio de umidade do solo de 40 a 100 cm de profundidade (fração).
v_soilm_100_200cm: Conteúdo volumétrico médio de umidade do solo de 100 a 200 cm de profundidade (fração)
soilt_0_10cm: Temperatura média do solo entre 0 e 10 cm de profundidade (C).
soilt_10_40cm: Temperatura média do solo a 10 a 40 cm de profundidade (C).
soilt_40_100cm: Temperatura média do solo entre 40 e 100 cm de profundidade (C).
soilt_100_200cm: Temperatura média do solo a 100 a 200 cm de profundidade (C).
Dados climatológicos e agro-climáticos tratados.
gdd: Graus dia acumulados com temperatura base de acordo com a cultura.
precip_temporal_max_diff: Diferença máxima entre semanas em precipitação na campanha.
precip_max: Valor de precipitação máxima em uma semana.
evapotranspiration_max_diff: Diferença máxima de evapotranspiração entre semanas durante a saf
rh_max_diff: Diferença máxima de umidade entre semanas durante a campanha.
skin_temporal_max_min_diff: Diferença máxima de temperatura do solo máx entre semanas durante a campanha.
skin_temporal_min_min_diff: Diferença máxima de temperatura do solo mínima entre semanas durante a campanha.
gdd_min_diff: Diferença de gdd entre semanas durante a campanha.
precip_first_month: Precipitação máxima alcançada durante o primeiro mês de campanha.
rh_first_month: Humidade máxima alcançada durante o primeiro mês da campanha.
skin_temp_max_first_month: Temperatura máxima do solo alcançada durante o primeiro mês da campanha.
solar_rad_first_month: Radiação solar máxima alcançada durante o primeiro mês de campanha.
Revisão dos dados
O primeiro passo é o cálculo de estatísticas de todas essas variáveis explicadas na seção anterior. Uma vez calculadas, procede-se a uma revisão automática das mesmas.
Atualmente, é gerado um relatório resumo desta revisão dos dados, podendo detectar:
Outliers temporais: Como problemas com as datas de plantio/colheita. Problemas com as variáveis preditoras (estimativas anômalas para uma cultura)
Outliers globais: Detecta algum problema de cálculo em todas as variáveis explicadas.
Tudo isso é representado em um relatório resumo como o seguinte:
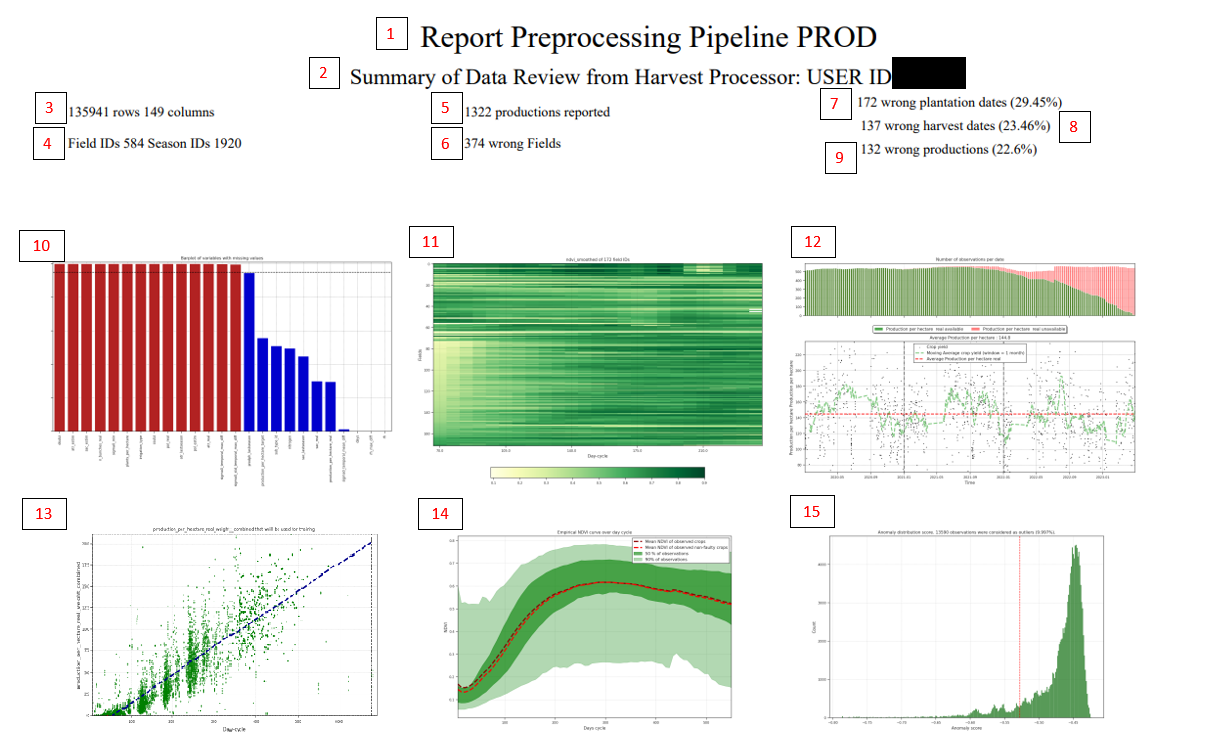
Indica o nome do relatório, nos indica que é um pré-processamento da variável PROD.
Nos dá informação do USER ID (cuidado para não confundir user_id com customer_id ou agrouser_id).
Indica-nos o tamanho do dataframe de dados.
Indica nº de campos e temporadas que esse cliente possui.
Nº de dado real para poder treinar (muito importante).
Nº de dados candidatos a serem considerados outliers.
Nº de safras que têm a data de plantio incorreta. Atualmente isso é registrado se o ndvi nos primeiros 30 dias for maior que 0,4 (para “sugarcane”, “beetroot”, “soybean”, “corn”, “cotton”). (Arquivo anexado no S3).
Nº de dados que se considera que a data de colheita está incorreta (Arquivo anexado no S3) levando em conta a data de plantio (por exemplo, temporadas muito longas ou curtas).
Nº de dados de produções reais que são considerados candidatos a outliers, fazemos dois desvios padrão sobre a média móvel dos dados no eixo dias. (Arquivo anexado no S3).
Gráfico onde nos indica nº de colunas que faltam dados e % de dados ausentes por variável.
Gráfico de evolução do NDVI por dias de cultivo para os season_ids que apresentam erros.
Evolução das produções em série temporal. O gráfico acima mostra a quantidade de dados com produção real (verde) com a de dados sem produção real reportada (vermelho). O gráfico abaixo mostra a evolução das produções reais reportadas.
Produção por dias de cultivo com os eixos limite para detectar os valores atípicos baseando-se em dados da série temporal utilizando a média populacional e dois terços (2/3) de desvio padrão sobre a média móvel.
Evolução do NDVI por dias de cultivo suavizadas por ciclo-dia das plantas.
Isolation forest: Mostra-nos a distribuição de scores em um histograma fornecida pelo algoritmo, e a quantidade de observações consideradas outliers. (https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html)
Todos os candidatos a outliers nos alertam sobre possíveis valores que não devem ser introduzidos no modelo, mas esse passo é realizado na seção seguinte.
Geração do modelo
A geração do modelo também é realizada de maneira automática.
Atualmente contamos com a geração automática de 3 modelos simultâneos realizando técnicas de hiperparametrização com o objetivo de obter o melhor modelo para os dados fornecidos.
Após o treinamento automático, também é gerado um relatório resumo de avaliação de resultados:
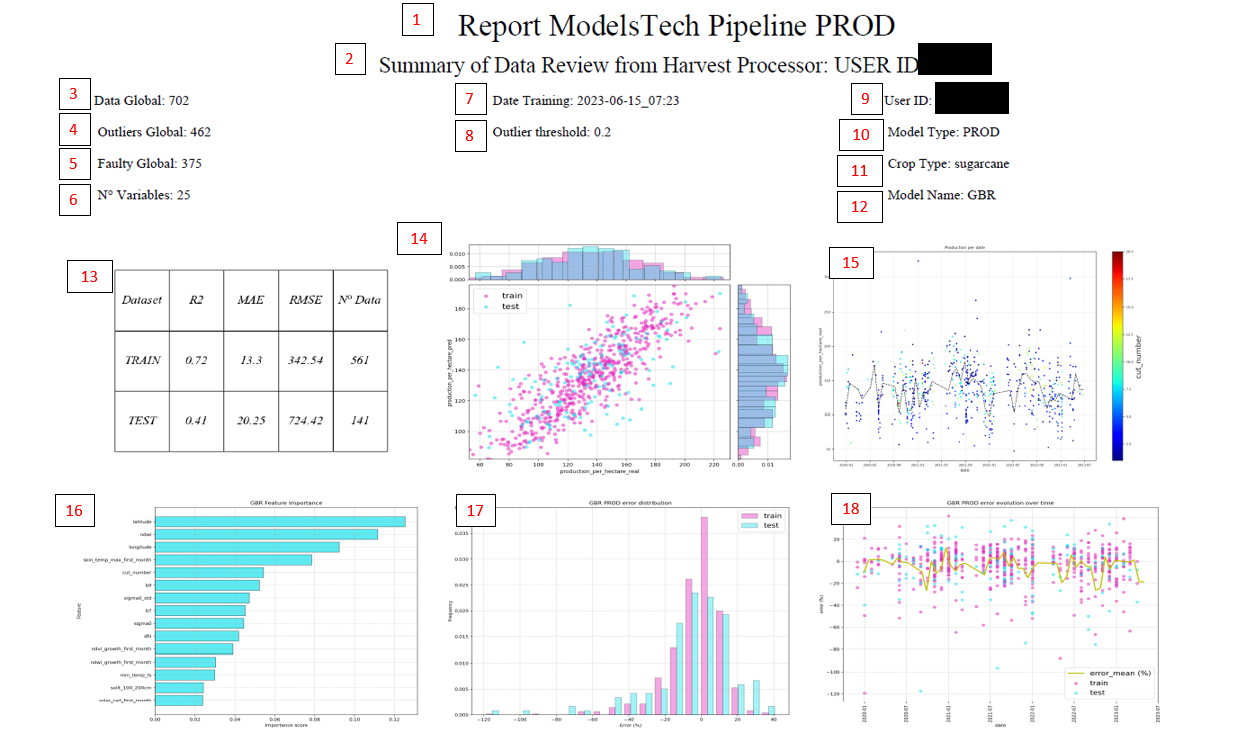
Título do relatório.
Indique o usuário do modelo.
Dados que finalmente entram no treinamento.
Outliers detectados com o isolation forest
Número de outliers no pré-processamento, como em ‘faulty_seasons_dict’
Nº de variáveis que entraram no modelo.
Data do treinamento.
O outlier_threshold que foi colocado no config.
Usuário do modelo.
Tipo de modelo.
Cultivo do modelo.
Tipo de modelo com a melhor acurácia (RFR -> Random Forest Regressor (serve para não fazer overfitting); GBR -> Gradient Boosting Regressor (intermediário, mas faz mais overfitting); XGBR -> eXtreme Gradient Boosting Regressor (é o que mais faz overfitting, mas também é o que geralmente apresenta melhores resultados)).
Tabela resumo das precisões.
Gráfico para verificar os dados reais vs previstos, distinguindo entre treino e teste.
Evolução das produções reais ao longo do tempo.
Variáveis mais importantes do modelo treinado.
Distribuição dos erros no treino e no teste. Se o treino e os testes são muito diferentes, então deve-se revisar o que aconteceu e por que os dados de teste não representam os de treinamento.
Distribuição do erro ao longo do tempo.
Além deste relatório resumo, também poderão ser consultados junto ao seu KAM/CPM gráficos de interesse para a análise dos dados em maior profundidade dentro do nosso gestor de modelos em produção (MLFLOW)
Geração de previsões
Depois que os dados foram revisados e treinados, usamos o modelo gerado para gerar previsões na campanha.
As previsões são atualizadas semanalmente. Para validar internamente os resultados, também geramos relatórios para garantir que tudo está funcionando corretamente e não detectamos fortes anomalias.
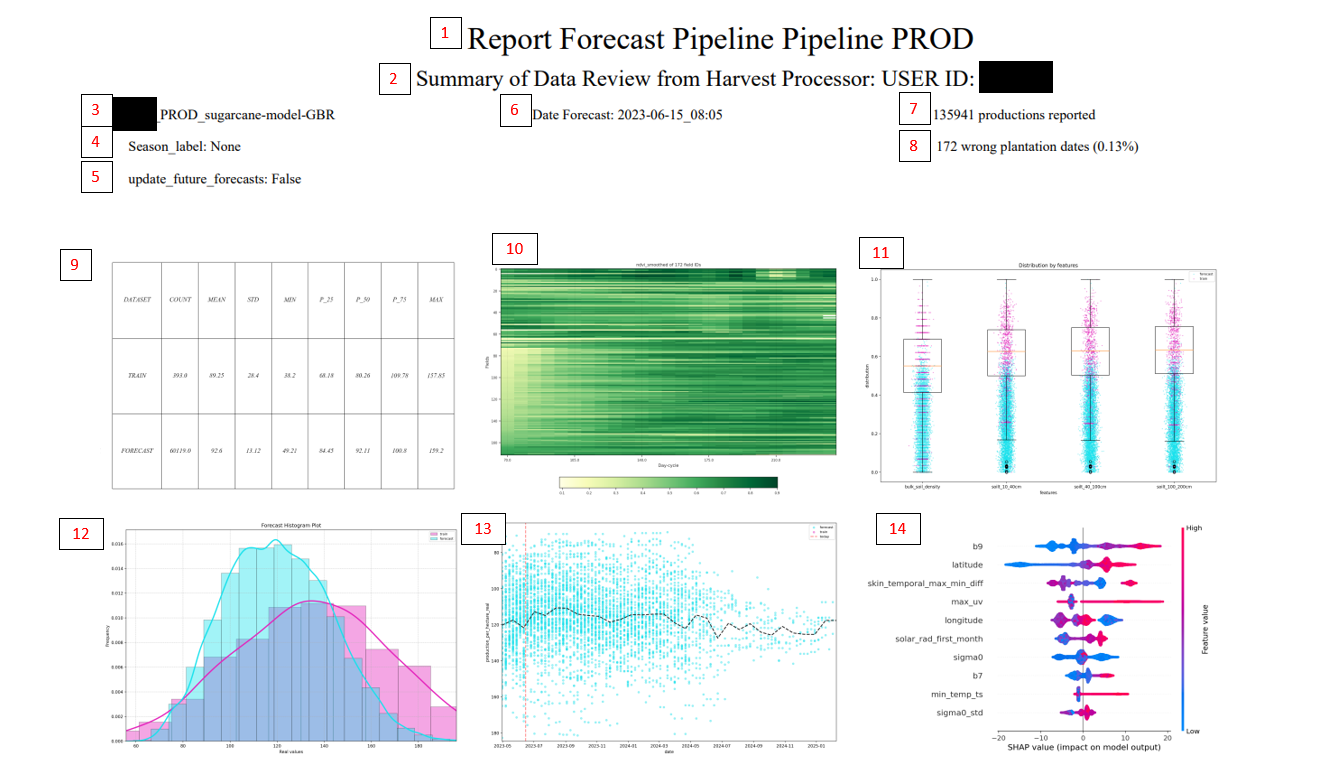
Título do relatório.
Indica o usuário para o qual foi realizada a predição.
Tipo de modelo.
Se algum filtro de season_label foi usado.
Se foi aplicado para atualizar apenas futuros ou tudo.
Data da previsão.
Número de predições geradas (para cada season_id existem múltiplas dates, por isso o número tão alto).
Parcelas que deveriam ter a data de plantio revisada.
Tabela resumo. Mostra as distribuições dos dados usados para treinar e os dados previstos. É normal que sempre haja um pequeno desvio entre a média do treino e a previsão, já que o treino considera apenas a data da colheita e a previsão considera tudo.
Gráfico resgatado do pré-processamento para poder detectar problemas de plantio.
Gráfico de distribuição das variáveis mais importantes do modelo, para ver a distribuição do modelo e os dados a prever
Frequência de dados segundo o valor a prever, segmentado com o treinado e o previsto
Evolução das estimativas ao longo do tempo, junto com os dados usados para treinar o modelo (se existirem dados do último ano usados para treiná-lo).
Variáveis com maior importância e como seus valores afetam a previsão. A linha vertical indica o valor esperado (E(X)). Em cada observação existe um valor para cada variável. O gráfico acima mostra como valores altos dessa variável (em vermelho) alteram a observação em relação ao valor esperado — por exemplo, a variável mais importante indica que valores vermelhos aumentam o valor da previsão em relação à média. Por outro lado, as cores azuis representam valores baixos dessa variável, e na variável mais importante vê‑se que valores baixos (cor azul) fazem com que a previsão seja menor.
API de Crop Predictor
Crop Predictor dispone de una API REST que permite consultar las predicciones generadas por los modelos de forma programática. La documentación interactiva (Swagger UI) está disponible en:
Producción: https://agropred.layers.hemav.com/docs
Autenticación
Todos los endpoints de la API requieren una API key que se pasa como parámetro de consulta (query parameter) en la URL:
?api_key=TU_API_KEY
Esta API key es la misma que se utiliza para cualquier interacción con las APIs de la plataforma Layers. Para obtenerla, contacta con tu KAM/CPM o utiliza el endpoint /publicapi/getApiKey de la API principal de Layers.
Si la API key no se proporciona, la API devolverá un error 401 Not authenticated. Si la API key no es válida o no se encuentra en el sistema, devolverá un error 403 API key not found.
Roles y permisos
El acceso a los datos está controlado por el rol asociado a la API key:
Rol |
Acceso |
|---|---|
Admin |
Acceso a todos los campos y usuarios |
Agrouser |
Campos de los clientes y cooperativas asignados |
Cooperativa |
Campos de los clientes miembros |
Cliente (Farmer) |
Solo sus propios campos |
Si se solicitan campos a los que la API key no tiene acceso, la API devolverá un error 403.
Endpoints
Health Check
Método |
Endpoint |
Descripción |
|---|---|---|
GET / HEAD |
|
Comprobación de disponibilidad del servicio |
POST /forecast
Endpoint principal para obtener las predicciones de productividad y calidad generadas por los modelos.
Parámetros de consulta (query):
Parámetro |
Tipo |
Requerido |
Descripción |
|---|---|---|---|
|
string |
Sí |
API key de autenticación |
Cuerpo de la petición (JSON):
Campo |
Tipo |
Requerido |
Descripción |
|---|---|---|---|
|
lista de strings |
Sí |
Lista de identificadores propios del cliente para sus campos (external reference). Cada cliente define sus propias referencias para identificar sus parcelas |
|
string (YYYY-MM-DD) |
Sí |
Fecha de inicio del rango de consulta |
|
string (YYYY-MM-DD) |
Sí |
Fecha de fin del rango de consulta |
Ejemplo de petición:
curl -X 'POST' \
'https://agropred.layers.hemav.com/forecast?api_key=TU_API_KEY' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"field_reference": [
"10001_500123"
],
"from_date": "2025-01-01",
"to_date": "2025-12-31"
}'
Ejemplo de respuesta exitosa (200):
La respuesta es un objeto JSON donde cada clave es una field_reference solicitada, y el valor es una lista de registros de predicción semanales.
{
"10001_500123": [
{
"date": "2025-01-05",
"season_id": "3012345",
"season_label": "SAFRA 2024-25",
"user_id": "10001",
"crop_type": "sugarcane",
"field_id": 500123,
"forecasts_production_per_hectare_real": 78.54,
"forecasts_atr_real": 132.17,
"update_date_production_per_hectare_real": "2025-04-10",
"update_date_atr_real": "2025-04-10",
"model.metadata.run_id_production_per_hectare_real": "abc123def456",
"model.metadata.run_id_atr_real": "789ghi012jkl"
},
{
"date": "2025-01-12",
"season_id": "3012345",
"season_label": "SAFRA 2024-25",
"user_id": "10001",
"crop_type": "sugarcane",
"field_id": 500123,
"forecasts_production_per_hectare_real": 79.12,
"forecasts_atr_real": 131.85,
"update_date_production_per_hectare_real": "2025-04-10",
"update_date_atr_real": "2025-04-10",
"model.metadata.run_id_production_per_hectare_real": "abc123def456",
"model.metadata.run_id_atr_real": "789ghi012jkl"
}
]
}
Descripción de los campos de respuesta:
Campo |
Tipo |
Descripción |
|---|---|---|
|
string |
Fecha de la predicción (resolución semanal) |
|
string |
Identificador de la campaña/zafra |
|
string |
Etiqueta legible de la campaña (ej: “SAFRA 2024-25”) |
|
string |
Identificador del usuario propietario |
|
string |
Tipo de cultivo (ej: “sugarcane”, “corn”, “soybean”) |
|
integer |
Identificador numérico de la parcela |
|
float |
Predicción de producción por hectárea (t/ha) |
|
float |
Predicción de ATR (Azúcares Totales Recuperables, kg/t) |
|
string |
Fecha de la última actualización del modelo de producción |
|
string |
Fecha de la última actualización del modelo de ATR |
|
string |
Identificador de la ejecución del modelo de producción (MLflow) |
|
string |
Identificador de la ejecución del modelo de ATR (MLflow) |
Nota
Los campos de predicción disponibles dependen del cultivo y de los modelos entrenados para cada cliente. Los campos más comunes son forecasts_production_per_hectare_real (producción) y forecasts_atr_real (ATR), pero pueden incluirse otros como forecasts_pol_real, forecasts_sac_real o forecasts_n_bunches_real según la configuración del modelo.
Nota
Los valores de update_date_* y model.metadata.run_id_* pueden estar vacíos ("") si la predicción aún no ha sido generada para ese modelo o fecha concreta.
Códigos de error:
Código |
Descripción |
|---|---|
|
API key no proporcionada |
|
API key no válida o sin permisos para los campos solicitados |
POST /s3/file_paths
Endpoint para obtener las rutas de los archivos generados por el sistema (reports de preprocessing, entrenamiento y predicción) almacenados en S3.
Parámetros de consulta (query):
Parámetro |
Tipo |
Requerido |
Descripción |
|---|---|---|---|
|
string |
Sí |
API key de autenticación |
Cuerpo de la petición (JSON):
Campo |
Tipo |
Requerido |
Descripción |
|---|---|---|---|
|
integer |
Sí |
Identificador del usuario cuyos archivos se desean consultar |
Ejemplo de petición:
curl -X 'POST' \
'https://agropred.layers.hemav.com/s3/file_paths?api_key=TU_API_KEY' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"user_id": 10001
}'
Ejemplo de respuesta exitosa (200):
[
"preprocessing/10001/report_prod_2025-03.pdf",
"training/10001/model_report_prod_2025-03.pdf",
"forecast/10001/forecast_report_prod_2025-04.pdf"
]
Códigos de error:
Código |
Descripción |
|---|---|
|
API key no proporcionada o sin permisos para el usuario solicitado |
|
API key no válida |
|
No hay archivos disponibles para el usuario |
Ejemplo de uso completo
A continuación se muestra un ejemplo completo de integración con la API utilizando Python:
import requests
API_URL = "https://agropred.layers.hemav.com"
API_KEY = "TU_API_KEY"
# Obtener predicciones para una parcela
response = requests.post(
f"{API_URL}/forecast",
params={"api_key": API_KEY},
json={
"field_reference": ["10001_500123"],
"from_date": "2025-01-01",
"to_date": "2025-12-31"
}
)
if response.status_code == 200:
data = response.json()
for field_ref, forecasts in data.items():
print(f"Parcela: {field_ref}")
for forecast in forecasts:
print(f" Fecha: {forecast['date']}")
print(f" Producción: {forecast.get('forecasts_production_per_hectare_real', 'N/A')} t/ha")
print(f" ATR: {forecast.get('forecasts_atr_real', 'N/A')} kg/t")
else:
print(f"Error {response.status_code}: {response.text}")
Dica
Puedes consultar múltiples parcelas en una sola petición pasando varias referencias en el array field_reference. La API procesará las consultas en paralelo para optimizar el tiempo de respuesta.